Capabilities
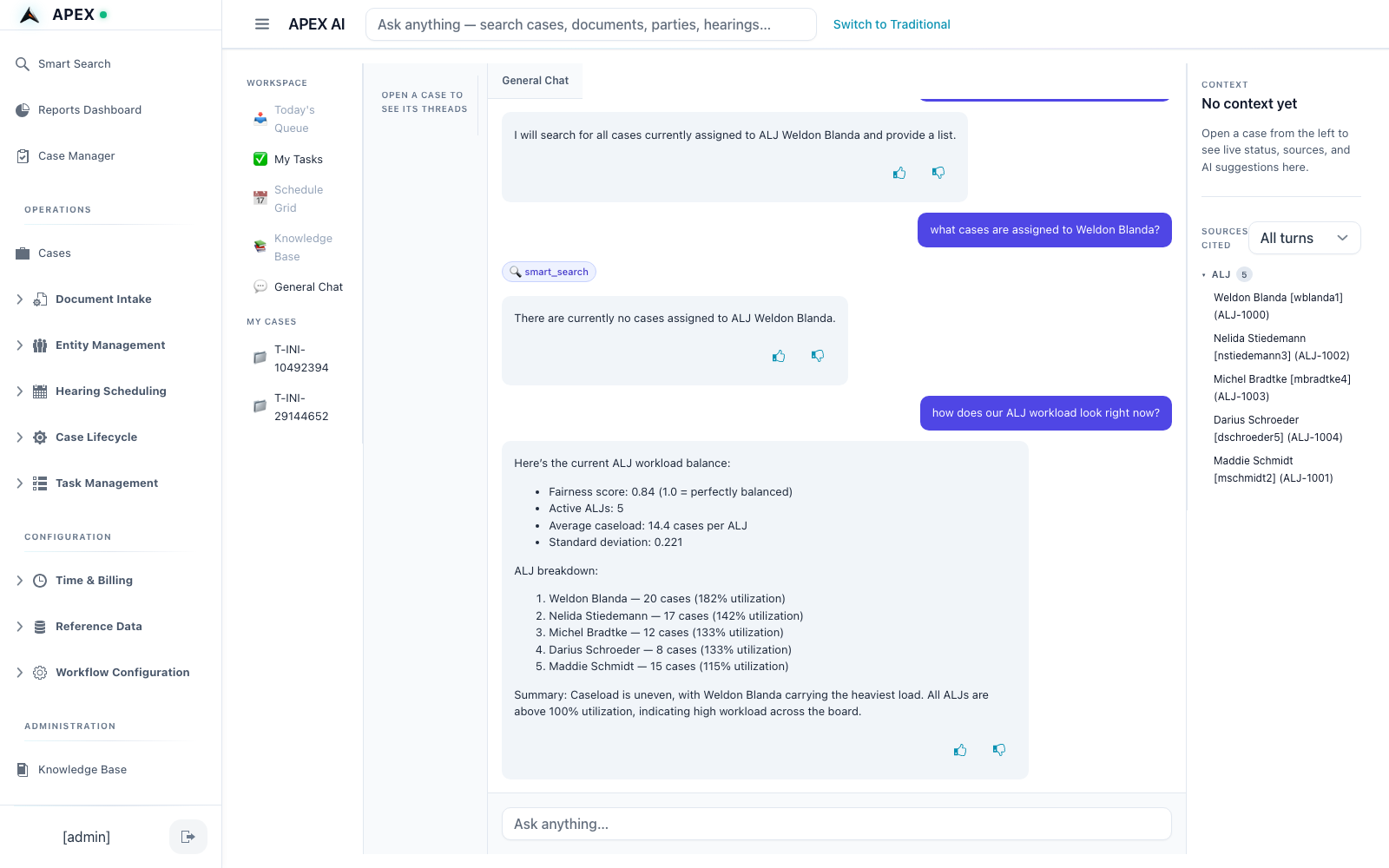
Thirty tools, one conversation.
Each tool is purpose-built, role-scoped, and audited. Selected highlights below — the full catalog ships in the demo.
🗓
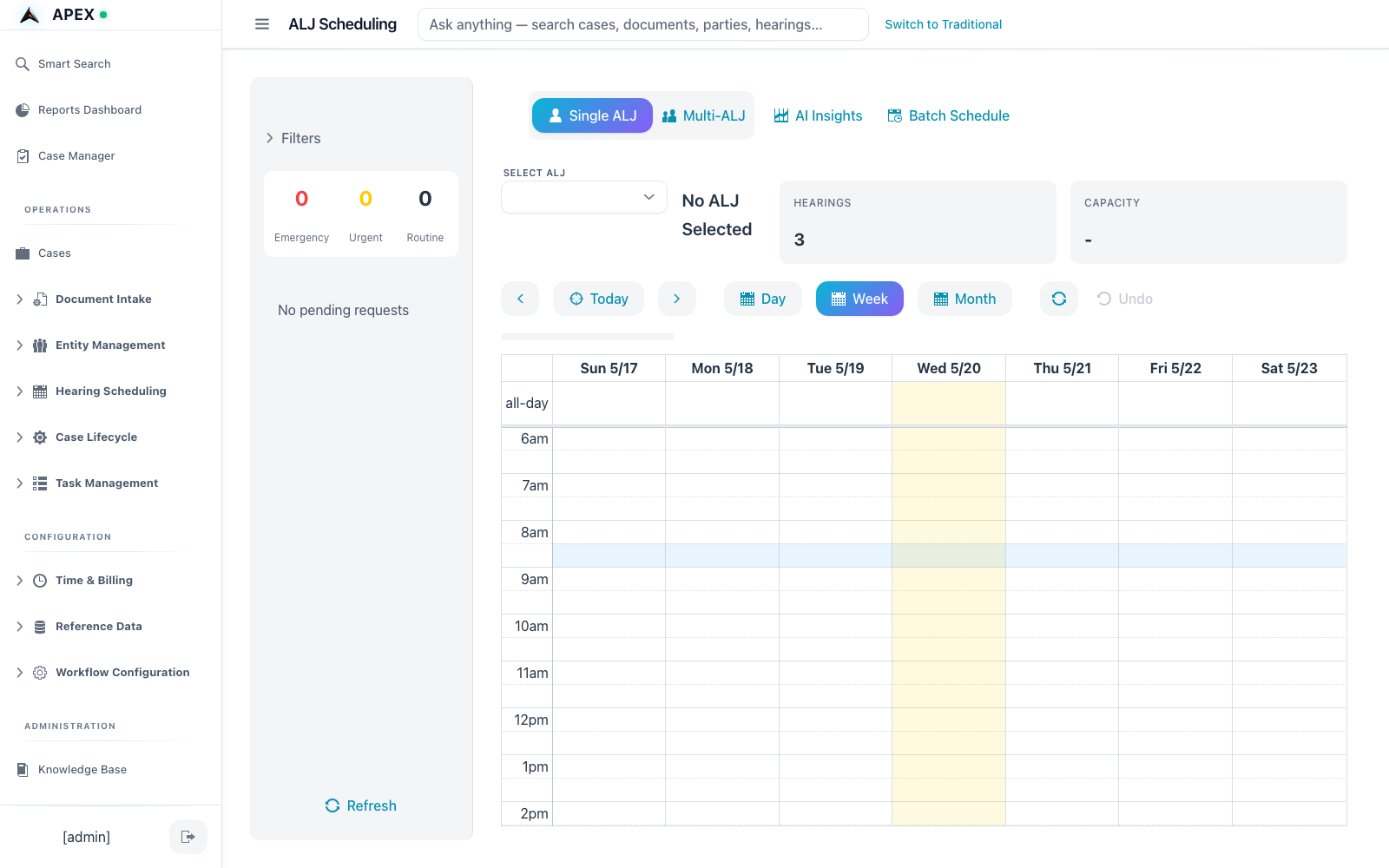
Intelligent scheduling
Score-ranked slots across ALJ availability, courtroom conflicts, interpreter needs, and hearing-format constraints. Predicts duration from your historical record.
⚖️
ALJ assignment
Ranks judges by workload, jurisdiction, specialization, and COI. Surfaces a justification with every recommendation.
🎭
Hearing rehearsal
Generates a realistic mock transcript grounded in the case facts — for counsel prep or judicial rehearsal. Stays inside the record. Never invents testimony.
✍️
Decision drafting
Drafts decisions from case context, prior filings, and applicable precedent. Every citation traces to a real entry. Every claim shows its source.
🔍
Grounded research
Synthesizes legal memos from the federal knowledge base. Vector + symbolic search. Refuses to answer when the corpus is silent.
⏱
Cascade-impact analysis
Before you reschedule a hearing, APEX shows every downstream hearing it would affect, every conflict it would create, and every buffer it would violate.
📊
Workload balance
Live fairness score across your bench. Spot overloaded judges before the next assignment.
🧠
Case memory
Long-term observations the AI remembers between conversations — pinnable, dismissable, audited.
🚨
Killswitch
One toggle disables every AI capability across the system. For incidents, audits, or maintenance windows.